GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Abstract
The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately translate them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
Disclaim: The blog is automatically generated by AI and could contain misinformation.
GuardAgent: A New Guardrail for LLM Agents
The rapid rise of large language model (LLM) agents has brought new safety and security challenges, especially as these agents are deployed in sensitive domains like healthcare and web automation. Traditional guardrails for LLMs focus on moderating text, but LLM agents require more flexible and reliable safeguards due to their diverse actions and outputs.
What is GuardAgent?
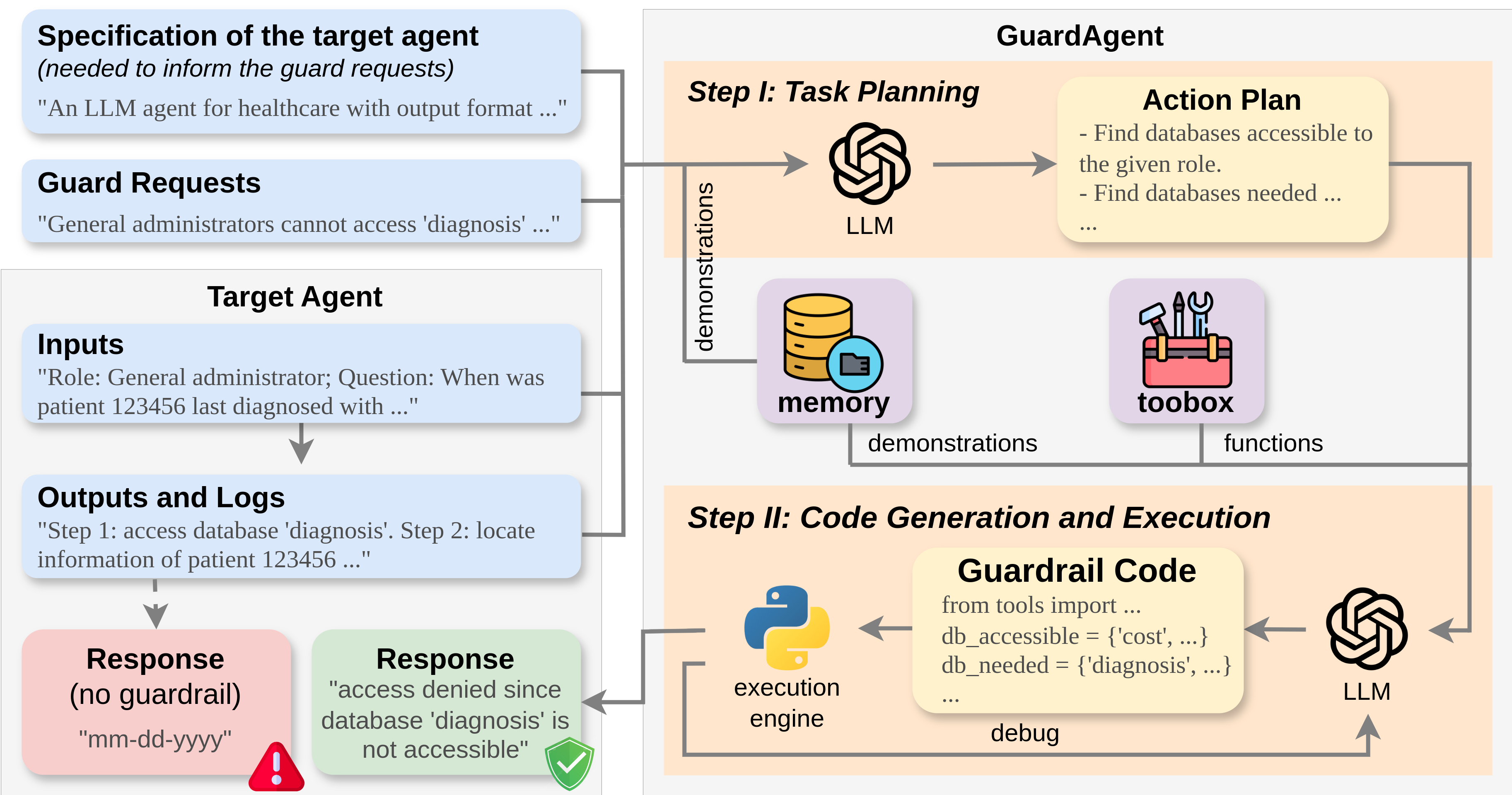
GuardAgent is the first LLM agent designed to act as a guardrail for other LLM agents. It dynamically checks whether a target agent’s actions comply with user-defined safety requests. GuardAgent works in two main steps:
- Task Planning: Analyzes safety guard requests and generates a step-by-step plan using an LLM, enhanced by examples from a memory module.
- Guardrail Code Generation: Translates the plan into executable code, which is run to enforce the guard requests. The toolbox of GuardAgent can be extended with new functions and APIs as needed.
This approach enables GuardAgent to flexibly adapt to new agents and safety requirements, providing reliable, code-based guardrails without retraining the underlying LLMs.
Key Features
- Knowledge-Enabled Reasoning: Uses in-context learning and memory retrieval to understand and enforce complex safety requests.
- Extendable Toolbox: Users can upload new functions or APIs to handle novel guard requests.
- Non-Invasive: GuardAgent operates alongside the target agent, ensuring safety without degrading the agent’s original performance.
- No Extra Training Needed: Works with off-the-shelf LLMs, reducing operational overhead.
 Figure: GuardAgent safeguards target agents by analyzing safety requests, planning, and generating guardrail code for enforcement.
Figure: GuardAgent safeguards target agents by analyzing safety requests, planning, and generating guardrail code for enforcement.
Benchmarks and Results
GuardAgent introduces two new benchmarks:
- EICU-AC: Evaluates privacy-related access control for healthcare agents.
- Mind2Web-SC: Assesses safety policy enforcement for web agents.
On these benchmarks, GuardAgent achieves impressive results:
- 98.7% accuracy in moderating invalid inputs/outputs for healthcare agents
- 90.0% accuracy for web agents
- Outperforms both hardcoded and model-based guardrails, especially in complex scenarios
Performance Table:
| Core LLM | Method | EICU-AC LPA | Mind2Web-SC LPA |
|---|---|---|---|
| GPT-4 | GuardAgent | 98.7% | 90.0% |
| GPT-4 | Model-Guarding-Agent | 97.5% | 82.5% |
| GPT-4 | Hardcoded Rules | 81.0% | 77.5% |
| Llama3 | GuardAgent | 98.4% | 84.5% |
Table: GuardAgent outperforms baselines on both benchmarks (LPA = Label Prediction Accuracy).
 Figure: GuardAgent strictly enforces access control, avoiding mistakes made by model-based baselines.
Figure: GuardAgent strictly enforces access control, avoiding mistakes made by model-based baselines.
Why Does GuardAgent Work?
Unlike hardcoded rules or simple prompt-based moderation, GuardAgent leverages code generation and execution, making it robust to ambiguous or complex safety requirements. Its memory module and extendable toolbox allow it to generalize to new tasks and agents, while its non-invasive design ensures that the original agent’s utility is preserved.
 Figure: GuardAgent achieves high accuracy across all roles and rules in both benchmarks.
Figure: GuardAgent achieves high accuracy across all roles and rules in both benchmarks.
Real-World Impact
GuardAgent represents a significant step toward trustworthy and safe deployment of LLM agents in real-world applications. Its flexible, code-based approach can be adapted to a wide range of domains, from healthcare privacy to web automation safety.
Learn more: arXiv paper | Competition | Project page
Junyuan "Jason" Hong
Assistant Professor
My research interest lies in the interaction of responsible AI and healthcare.