LLM-PBE: Assessing Data Privacy in Large Language Models
Abstract
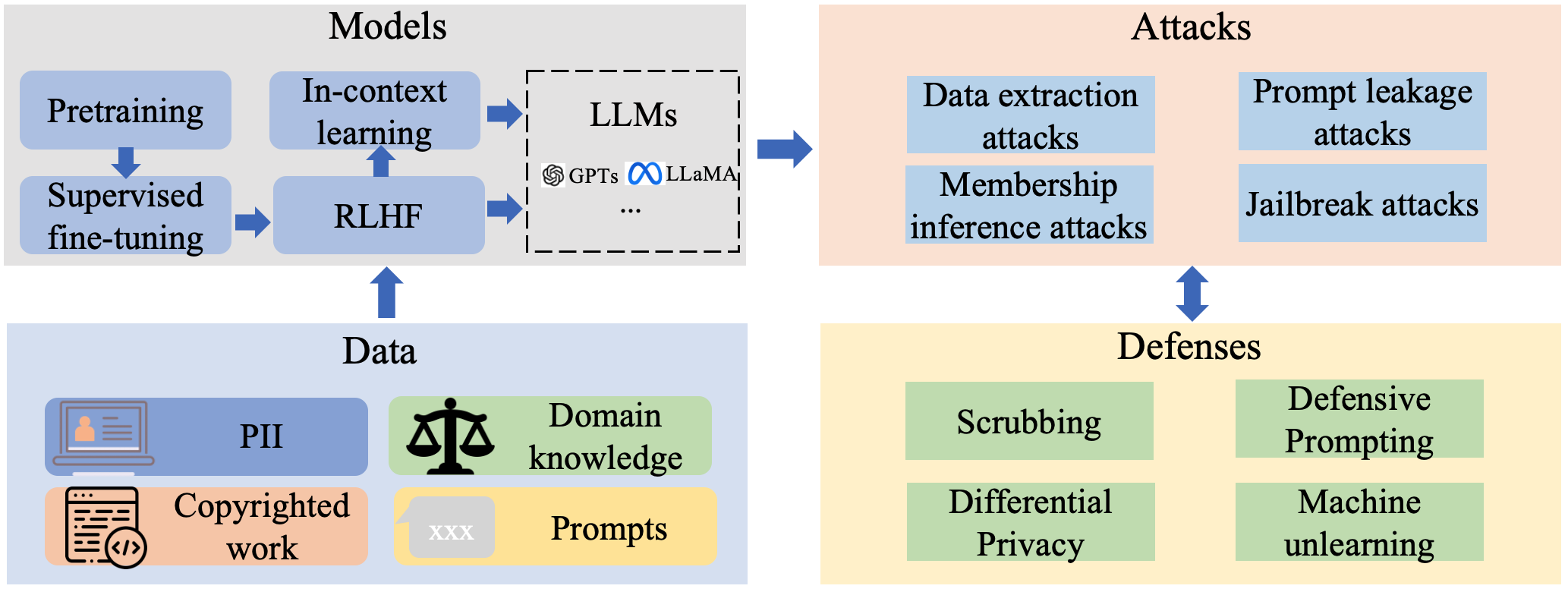
Large Language Models (LLMs) have swiftly become integral to numerous technological domains, significantly advancing applications in data management, mining, and analysis. Their profound capabilities in processing and interpreting complex language data, however, bring to light pressing concerns regarding data privacy, especially the risk of unintentional training data leakage. Despite the critical nature of this issue, there has been no existing literature to offer a comprehensive assessment of data privacy risks in LLMs. Addressing this gap, our paper introduces LLM-PBE, a toolkit crafted specifically for the systematic evaluation of data privacy risks in LLMs. LLM-PBE is designed to analyze privacy across the entire lifecycle of LLMs, incorporating diverse attack and defense strategies, and handling various data types and metrics. Through detailed experimentation with multiple LLMs, LLM-PBE facilitates an in-depth exploration of data privacy concerns, shedding light on influential factors such as model size, data characteristics, and evolving temporal dimensions. This study not only enriches the understanding of privacy issues in LLMs but also serves as a vital resource for future research in the field. Aimed at enhancing the breadth of knowledge in this area, the findings, resources, and our full technical report are made available at https://llm-pbe.github.io/ , providing an open platform for academic and practical advancements in LLM privacy assessment.
Junyuan "Jason" Hong
Assistant Professor
My research interest lies in the interaction of responsible AI and healthcare.