Abstract
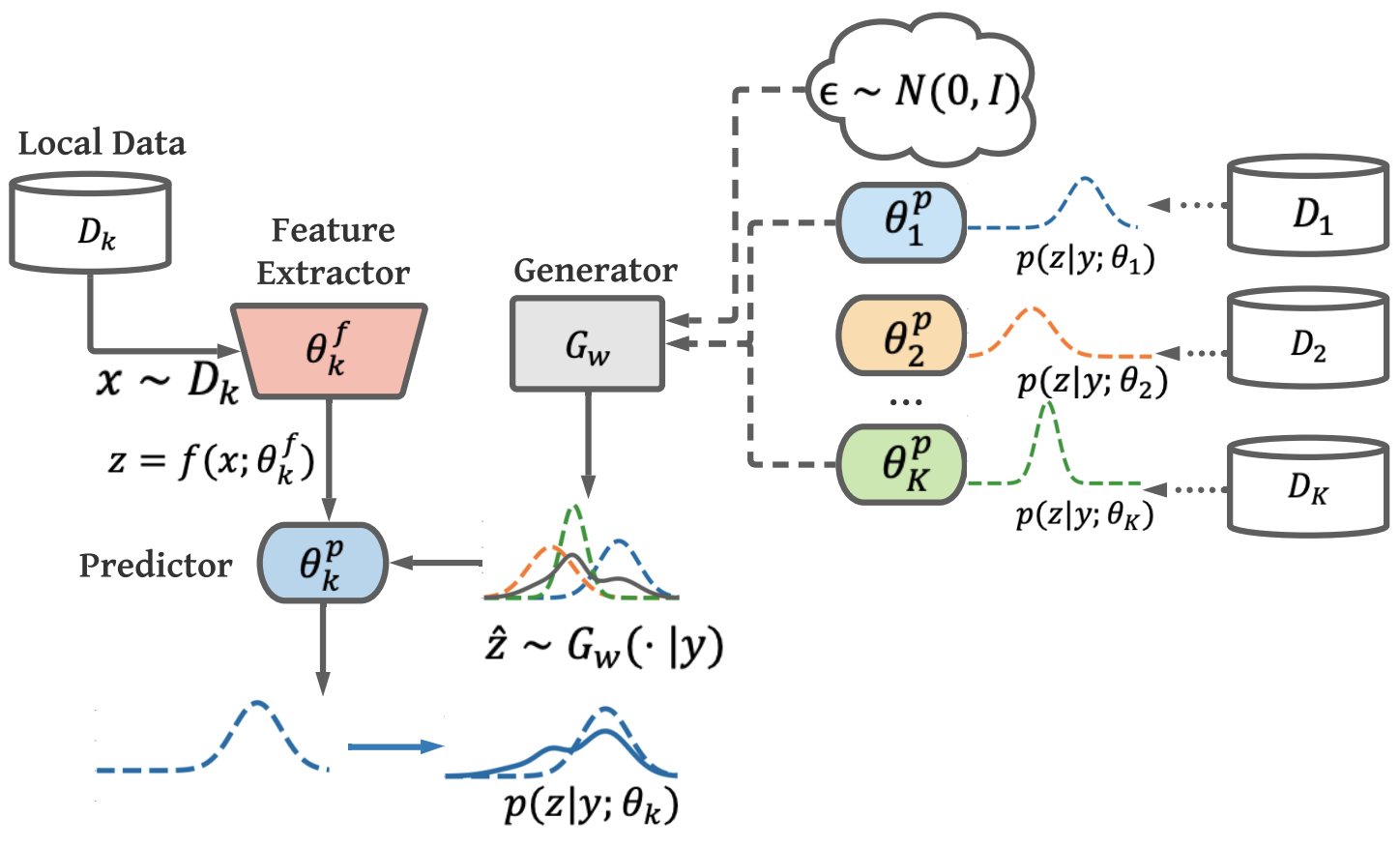
Federated Learning (FL) is a decentralized machine-learning paradigm, in which a global server iteratively averages the model parameters of local users without accessing their data. User heterogeneity has imposed significant challenges to FL, which can incur drifted global models that are slow to converge. Knowledge Distillation has recently emerged to tackle this issue, by refining the server model using aggregated knowledge from heterogeneous users, other than directly averaging their model parameters. This approach, however, depends on a proxy dataset, making it impractical unless such a prerequisite is satisfied. Moreover, the ensemble knowledge is not fully utilized to guide local model learning, which may in turn affect the quality of the aggregated model. Inspired by the prior art, we propose a data-free knowledge distillation approach to address heterogeneous FL, where the server learns a lightweight generator to ensemble user information in a data-free manner, which is then broadcasted to users, regulating local training using the learned knowledge as an inductive bias. Empirical studies powered by theoretical implications show that our approach facilitates FL with better generalization performance using fewer communication rounds, compared with the state-of-the-art.
Junyuan "Jason" Hong
Assistant Professor
My research interest lies in the interaction of responsible AI and healthcare.