Abstract
Data-free knowledge distillation (KD) helps transfer knowledge from a pre-trained model (known as the teacher model) to a smaller model (known as the student model) without access to the original training data used for training the teacher model. However, the security of the synthetic or out-of-distribution (OOD) data required in data-free KD is largely unknown and under-explored. In this work, we make the first effort to uncover the security risk of data-free KD w.r.t. untrusted pre-trained models. We then propose Anti-Backdoor Data-Free KD (ABD), the first plug-in defensive method for data-free KD methods to mitigate the chance of potential backdoors being transferred. We empirically evaluate the effectiveness of our proposed ABD in diminishing transferred backdoor knowledge while maintaining compatible downstream performances as the vanilla KD. We envision this work as a milestone for alarming and mitigating the potential backdoors in data-free KD. Codes are released at https://github.com/illidanlab/ABD.
To tailor the highly performant large models for the budget-constrained devices, knowledge distillation (KD) and more recently data-free KD, has emerged as a fundamental tool in the DL community. Data-free KD, in particular, can transfer knowledge from a pre-trained large model (known as the teacher model) to a smaller model (known as the student model) without access to the original training data of the teacher model. The non-requirement of training data generalizes KD to broad real-world scenarios, where data access is restricted for privacy and security concerns. For instance, many countries have strict laws on accessing facial images, financial records, and medical information.
Despite the benefits of data-free KD and the vital role it has been playing, a major security concern has been overlooked in its development and implementation: Can a student trust the knowledge transferred from an untrusted teacher? The untrustworthiness comes from the non-trivial chance that pre-trained models could be retrieved from non-sanitized or unverifiable sources, for example, third-party model vendors or malicious clients in federated learning. One significant risk is from the backdoor pre-implanted into a teacher model, which alters model behaviors drastically in the presence of predesigned triggers but remains silent on clean samples. As traditional attacks typically require to poison training data, it remains unclear if student models distilled from a poisoned teacher will suffer from the same threat without using the poisoned data.


In this paper, we take the first leap to uncover the data-free backdoor transfer from a poisoned teacher to a student through comprehensive experiments on 10 backdoor attacks. We evaluated one vanilla KD using clean training data and three training-data-free KD method which use synthetic data (ZSKT1 & CMI 2) or out-of-distribution (OOD) data as surrogate distillation data3.
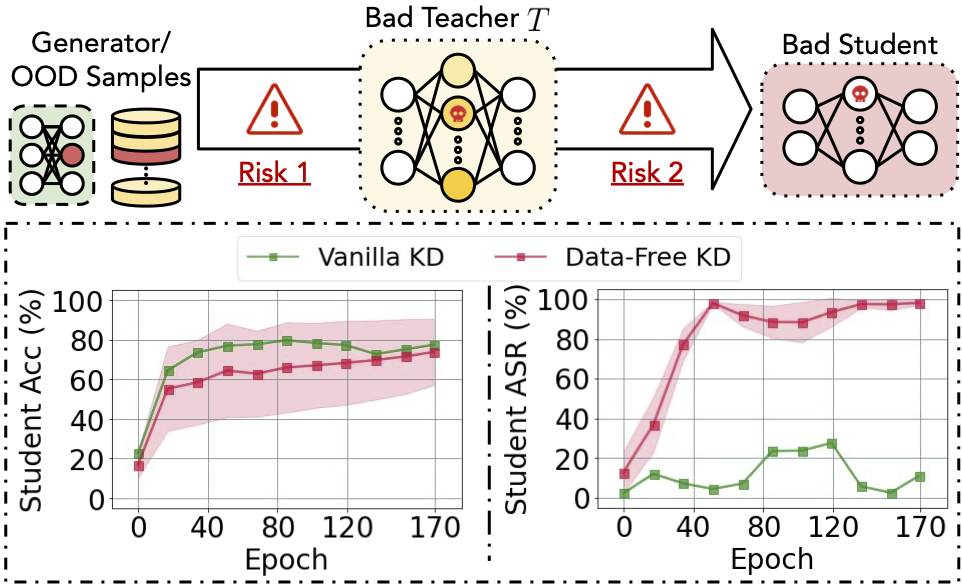
Our main observations are summarized as follows and essentially imply two identified risks in data-free KD.
- Vanilla KD does not transfer backdoors by using clean in-distribution data, while all three training-data-free distillations suffer from backdoor transfer by 3 to 8 types of triggers out of 10 with a more than 90% attack success rate. Contradicting the two results indicates the poisonous nature of the surrogate distillation data in data-free KD.
- The successful attack on distillation using trigger-free out-of-distribution (OOD) data demonstrate that triggers are not essential for backdoor injection, but the poisoned teacher supervision is.

Upon observing the two identified risks, we propose a plug-in defensive method, Anti-Backdoor Data-Free KD (ABD), that works with general data-free KD frameworks. ABD aims to suppress and remove any backdoor knowledge being transferred to the student, thus mitigating the impact of backdoors. The high-level idea of ABD is two-fold: (SV) Shuffling Vaccine during distillation:~suppress samples containing potential backdoor knowledge being fed to the teacher (mitigating backdoor information participates in the KD); Student (SR) Self-Retrospection after distillation:~ synthesize potential learned backdoor knowledge and unlearns them at later training epochs (the backstop to unlearn acquired malicious knowledge). ABD is effective on defending various backdoor attacks with different patterns and is a plug-in defense that can be used seamlessly with all three types of data-free KD.
-
Micaelli, P., & Storkey, A. J. (2019). Zero-shot knowledge transfer via adversarial belief matching. NeurIPS. ↩︎
-
Fang, G., Song, J., Wang, X., Shen, C., Wang, X., & Song, M. (2021). Contrastive model inversion for data-free knowledge distillation. IJCAI. ↩︎
-
Asano, Y. M., & Saeed, A. (2023). Extrapolating from a single image to a thousand classes using distillation. ICLR. ↩︎
Junyuan "Jason" Hong
Assistant Professor
My research interest lies in the interaction of responsible AI and healthcare.