Dynamic Privacy Budget Allocation Improves Data Efficiency of Differentially Private Gradient Descent
Abstract
Protecting privacy in learning while maintaining the model performance has become increasingly critical in many applications that involve sensitive data. Private Gradient Descent (PGD) is a commonly used private learning framework, which noises gradients based on the Differential Privacy protocol. Recent studies show that dynamic privacy schedules of decreasing noise magnitudes can improve loss at the final iteration, and yet theoretical understandings of the effectiveness of such schedules and their connections to optimization algorithms remain limited. In this paper, we provide comprehensive analysis of noise influence in dynamic privacy schedules to answer these critical questions. We first present a dynamic noise schedule minimizing the utility upper bound of PGD, and show how the noise influence from each optimization step collectively impacts utility of the final model. Our study also reveals how impacts from dynamic noise influence change when momentum is used. We empirically show the connection exists for general non-convex losses, and the influence is greatly impacted by the loss curvature.
Utility upper bounds are a critical metric for privacy schedules, which characterizes the maximum utility that a schedule can deliver in theory. Wang et al. [34] is the first to prove the utility bound under the PL condition. Recently, Zhou et al. proved the utility bound by using the momentum of gradients [17, 25]. In this paper, we improve the upper bound by a more accurate estimation of the dynamic influence of step noise. We show that introducing a dynamic schedule further boosts the sample-efficiency of the upper bound. Table 1 summarizes the upper bounds of a selection of state-of-the-art algorithms based on private gradients (up block, see Appendix B for the full list), and methods studied in this paper (down block), showing the benefits of dynamic influence.
Especially, a closely-related work by Feldman et al. achieved a convergence rate similar to ours in terms of generalization error bounds (c.f. SSGD in Table 2), by dynamically adjusting batch sizes [11]. However, the approach requires controllable batch sizes, which may not be feasible in many applications. In federated learning, for example, where users update models locally and then pass the parameters to server for aggregation, the server has no control over batch sizes, and coordinating users to use varying batch sizes may not be realistic. On the other hand, our proposed method can still be applied for enhancing utility, as the server can dynamically allocate privacy budget for each round when the presence of a user in the global aggregation is privatized [21].

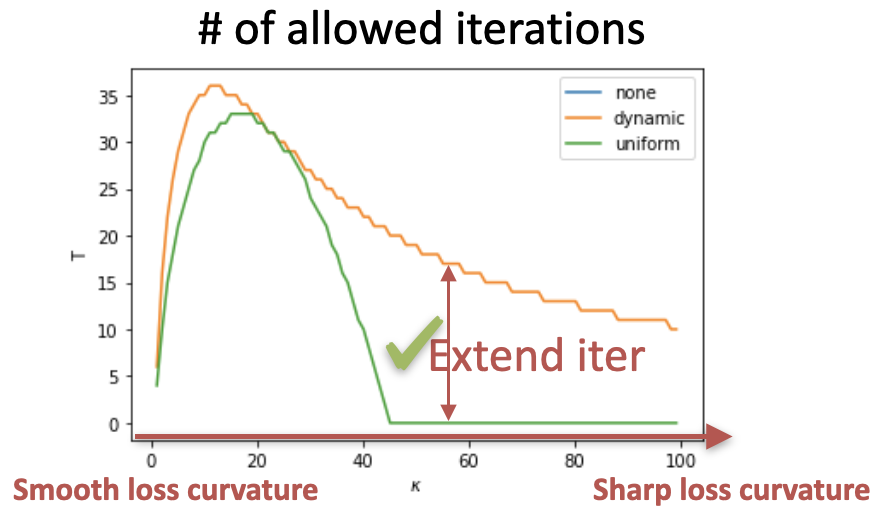
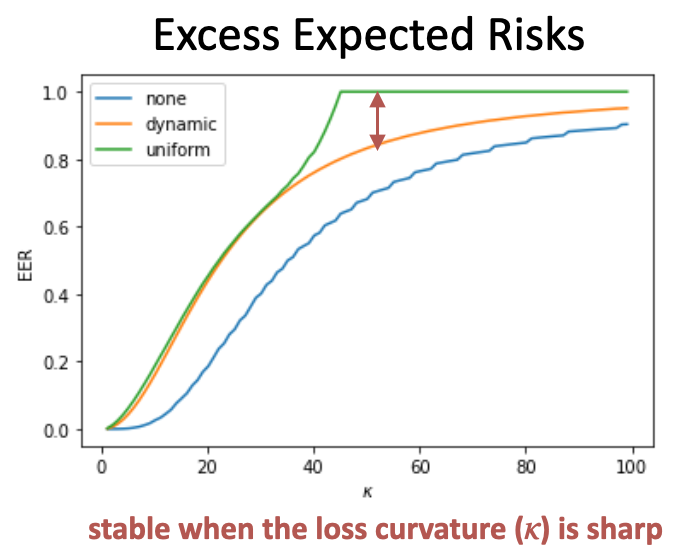
In brief, given a sharper loss function, the dynamic budget allocation allows the DPSGD to run for more private iterations and results in lower excess expected risks.
Junyuan "Jason" Hong
Assistant Professor
My research interest lies in the interaction of responsible AI and healthcare.